나를 학습한 AI가 돈을 벌었다. 나의 몫은?
2023-01-10
alookso 재직 당시 게재한 글.
오보를 통해 살펴본 AI시대 저작권 문제
‘제2의 러다이트’ 운동?
때는 2022년 12월 14일, 장소는 아트스테이션(ArtStation)이라는 웹사이트입니다. 영화, 게임, 만화 등에 종사하는 시각예술 창작자들이 작업을 공유하는 플랫폼입니다. 탐색 페이지 ‘트렌딩’ 탭이 평소와는 다른 모습입니다. 글쓴 시점 기준 트렌딩 탭에 주로 보이는 것은 여성 캐릭터, 고딕풍의 몬스터, 스팀펑크나 판타지 세계 풍경, 정밀한 총기 묘사 등입니다. 하지만 유독 12월 14일의 아트스테이션은 “AI”라는 단어 위에 금지 픽토그램(🚫)을 얹은 이미지로 가득합니다.
 출처: 인터넷 아카이브
출처: 인터넷 아카이브
이 장면의 배경에는 빠르게 대중화한 이미지 생성AI가 있습니다. 아트스테이션에 AI로 생성한 이미지를 게시하는 이용자들이 등장한 것이죠. 일각에서는 AI 생성물이 인간 창작자의 작업을 훔치는 행위라며 반발했고, 플랫폼의 대응을 이끌어내고자 집단적/집중적으로 “No to AI” (AI 반대) 로고를 게시한 것입니다.
더에이아이 보도에 따르면 AI 생성 이미지 반대 시위는 아트스테이션을 넘어 AI 자체에도 타격을 주었습니다. 이미지 생성툴 미드저니가 ‘교과서’로 삼고 있는 아트스테이션 데이터를 학습한 뒤 AI 반대 로고가 뒤섞인 그림이 나오기 시작했다는 겁니다. 아래 트윗에 첨부된 이미지처럼요. 해당 보도는 이용자들의 AI 반대 시위를 “제2의 러다이트” 운동으로 규정했습니다. 창작 노동자들의 생계를 위협하는 자동화 기술에 저항하여 조직한 집단 행동이 신기술을 사보타주했다는 점에서, 과연 러다이트 운동에 견줄 만한 일이었습니다.

Oh shit, their attack has already reached MidJourney training, check out how all my generations are now ruined! pic.twitter.com/PccaS2RFZA
— Roope Rainisto (@rainisto) December 14, 2022
트윗 번역: “이런, [시위대의] 공격이 벌써 미드저니 학습 단계에까지 도달했네. 내가 생성한 이미지 죄다 망가진 것 좀 보라구!”
그런 일이 실제로 일어난 적 없다는 것만 빼면요. 미드저니 같은 거대 생성모델은 실시간으로 신규 데이터를 반영하지 않습니다. 모델을 한 번 구축하는 데 워낙 시간과 돈이 많이 들기 때문입니다. ‘오염된 데이터를 학습’한 결과로 만들어졌다는 위 트윗의 이미지는 해당 사용자의 트롤링으로 보아야 합니다. 아트스테이션 풍의 그림을 만들기 위해 ‘trending on artstation‘이라는 문구가 자주 사용되는 현상을 보고, 아트스테이션의 현재 상태도 생성AI에 영향을 줄 것이라고 오해한 사람들을 조롱한 거죠. ‘제2의 러다이트’ 운동의 소위 ‘결과물’은 AI가 아니라 인간이 가짜로 생성한 것이었습니다.
하지만 이 오해는 비록 세부사항에서는 틀렸을지언정, AI 기술의 근간을 건드리는 중요한 질문과 연결되어 있습니다. 바로 이미지 생성 AI 제작에 활용되는 인간 창작자의 그림, 즉 데이터셋의 문제입니다.
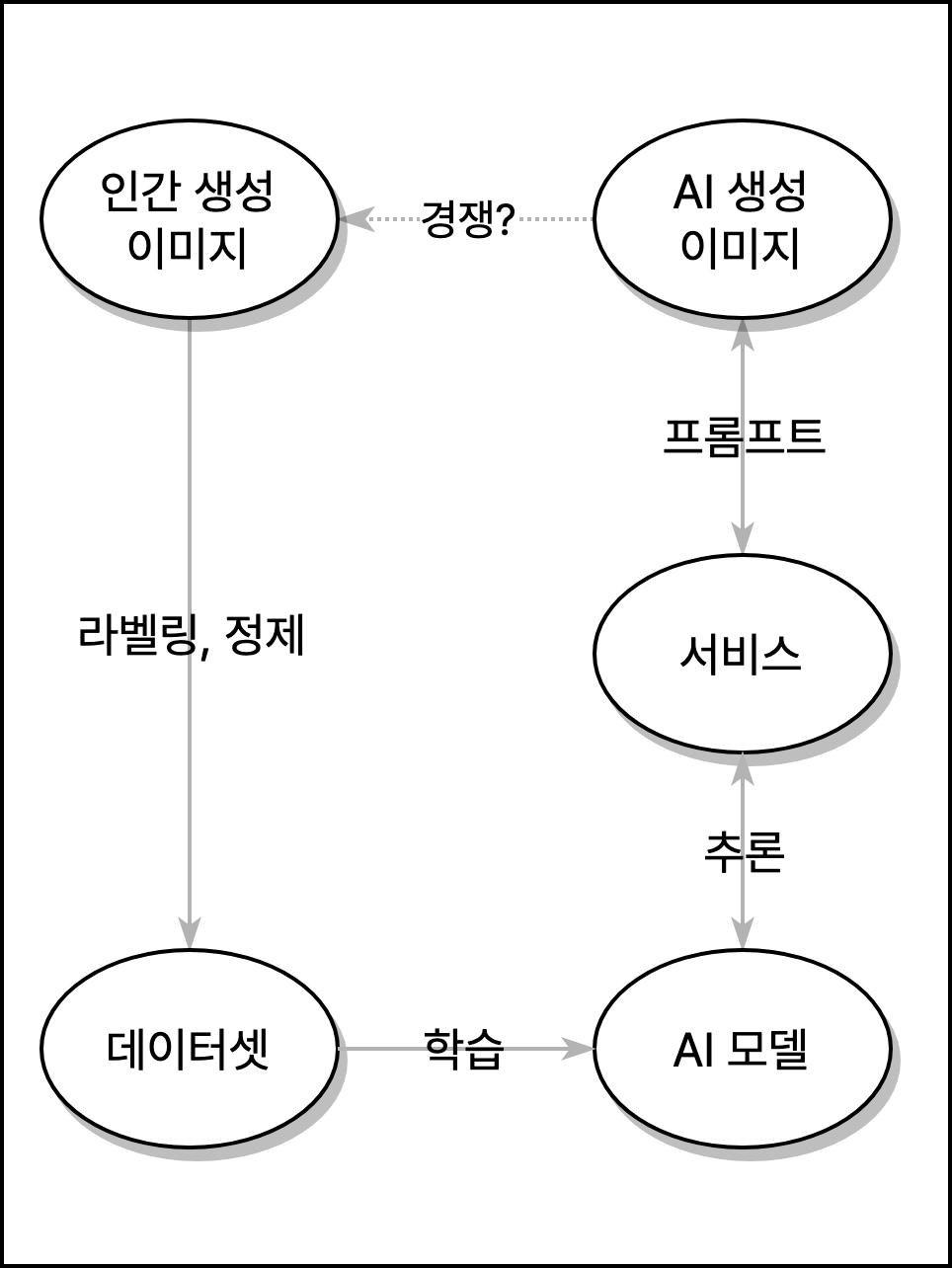 이미지 - 데이터셋 - 모델 - 서비스의 관계를 단순화한 도식. 자체제작
이미지 - 데이터셋 - 모델 - 서비스의 관계를 단순화한 도식. 자체제작
인간 창작물에서 AI생성 이미지까지
AI 반대 시위가 겨냥한 AI생성 이미지가 어떤 과정을 거쳐 만들어지는지 간단히 짚어봅시다. 이미지를 생성하는 사용자는 보통 미드저니, 달리, 드림스튜디오 등의 서비스를 이용합니다. 이들 서비스는 텍스트 명령어(프롬프트)를 생성AI 모델에 입력하여, 그 결과로 계산된 이미지를 사용자에게 전달해주는 인터페이스를 제공합니다. 이미지 생성AI는 특정 텍스트가 주어졌을 때 그에 부합하는 이미지를 추론하는 통계 모형입니다. 이 모형을 만들기 위해 이미지와 그 이미지를 묘사하는 텍스트가 결합된 자료를 억 단위로 학습합니다. 이런 데이터셋은 대부분 인터넷에 올라온 웹페이지를 대량으로 수집한 뒤 일정 기준에 따라 선별, 정제하여 구축합니다. 그리고 인터넷에 있는 이미지 중에는 아트스테이션 사용자들이 공유하는 그림 같은 저작물이 많이 포함되어 있습니다.
 스테이블 디퓨전(드림스튜디오)에 자본가(capitalist), 유전(oil rig), 채굴(mining) 등의 키워드를 입력해 생성한 이미지. 자체제작
스테이블 디퓨전(드림스튜디오)에 자본가(capitalist), 유전(oil rig), 채굴(mining) 등의 키워드를 입력해 생성한 이미지. 자체제작
이제는 상투적인 표현으로 “데이터는 디지털 경제 시대의 원유”라는 말이 있습니다. 국무총리 산하 국가데이터정책위원회 보도자료에 등장하는 구절로, 데이터를 마치 천연자원처럼 추출하고 정제하여 가치를 만들어낸다는 의미입니다. 생성AI에서도 마찬가지로, 사용자가 이미지를 활용해 수익 활동을 할 때뿐만 아니라 그에 앞서 서비스, 모델, 데이터셋을 구축하는 각 단계에서 경제적 가치가 발생합니다. 서비스는 모델에 대한 접근 편의를 상품화하여 수익을 얻습니다. 모델과 데이터셋을 구축하는 단계의 수익 구조는 그보다 불명확한 편이지만, 데이터셋과 인공지능 구축 능력은 자본의 관심을 끕니다. 달리를 만든 오픈AI는 마이크로소프트의 10억달러 투자를 받은 바 있으며 스테이블 디퓨전을 보급하는 스태빌리티AI도 1억달러를 유치했습니다.
그런데 사람의 창작물을 석유에 빗대는 것이 적절한 비유일까요? 문제는 위의 과정과 이윤이 저작권 보호 대상을 포함하고 있는 데이터셋에 바탕을 두고 있다는 것입니다. AI 학습 데이터는 개별 저작권자의 동의 절차 없이 활용됩니다. 미드저니 CEO 데이비드 홀츠도 인정하듯, “1억 개의 이미지를 확보하면서 그 출처를 파악할 방법”은 (적어도 지금은) 없는 것입니다. 그렇다면 ‘남의 작업’을 활용해 이윤을 만들어내는 일은 정당할까요?
![]()
스테이블 디퓨전(드림스튜디오)에 여성 예술가(woman artist), 보상(payment), 아트스테이션 트렌딩에 올라온(trending on artstation) 등의 키워드를 입력해 생성한 이미지. 자체제작
공정이용, 거부권, 데이터 배당금
아직 확실치 않습니다. 일각에서는 저작물을 활용한 AI학습이 공정이용에 해당한다고 주장하기도 합니다. 더 버지 보도에서는 학술/비영리 활동을 통한 “데이터 세탁”이 공정이용 인정 가능성을 높일 수 있다고 지적합니다. 스테이블 디퓨전을 적극 상용화하고 있는 스태빌리티AI는 모델을 직접 만드는 대신, 독일 뮌헨대학교 연구진이 모델을 구축할 수 있도록 자금과 인프라를 지원한 뒤 연구진이 공개 라이선스로 발표한 모델을 사용했습니다. 한편 앞서 데이터가 원유라고 표현한 국가데이터정책위원회는 “인공지능 학습 등 빅데이터 분석 시 개별 저작물을 우선 이용할 수 있도록 허용”하는 저작권법 규정을 신설하겠다고 밝힌 바 있습니다.
하지만 단국대 법학연구소 교수 김도경이 지적하듯 생성AI의 결과물이 학습데이터로 사용된 저작물의 지위를 위협하거나 (아트스테이션에 올라온 AI생성 이미지처럼요), 나아가 원저작자의 직군 자체를 위협할 수도 있다는 점은 공정이용 주장의 반대 근거가 될 만합니다. (“인공지능 시대에 저작권 보호와 공정한 이용의 재고찰”, 2021). 김도경은 공정이용이 “저작권자의 경제적 권리를 제한하여 특정 이용목적의 이용자에게 보조금을 지급하는 것”이고, 수많은 인터넷 이용자의 데이터로 학습한 AI를 공정이용으로 무조건 인정하면 부(富)를 “대중으로부터 우위를 점하고 있는 기업으로 이동”시킬 우려가 있다고 지적합니다.
공정이용에 대한 법적 판단을 기다리기에 앞서 저작권자의 의사를 반영하려는 사례도 있습니다. 아트스테이션은 이용자들의 시위로 홍역을 치른 후, 게시물이 AI학습에 사용되는 것을 거부하는 옵션을 신설했습니다. 스태빌리티AI 또한 스테이블 디퓨전 다음 버전에서는 창작자가 거부 의사를 밝힌 자료를 사용하지 않겠다고 밝혔습니다. 검색 도구인 haveibeentrained에서 자신의 작업물을 찾아보고 거부를 신청하는 방식입니다. 두 사례 모두 거부 의사를 적극적으로 밝힌 경우에만 제외해주는 접근(opt-out)이라는 한계가 있지만, 관련 논의가 업계 행위자들에게도 영향을 주고 있음을 드러냅니다.
위 사례들이 ‘사용해도 되는지’의 문제에 답하려는 시도라면, 사용한 데이터의 생산자에게 대가를 지급하는 접근 또한 등장하고 있습니다. 이미지 서비스 셔터스톡은 오픈AI와 협력 관계를 맺고, 달리 같은 생성모델이나 데이터셋 구축에 활용된 이미지의 창작자에게 수익의 일정 부분을 지급하는 계획을 발표했습니다. 일종의 로열티 내지 데이터 배당 개념입니다. 다만 셔터스톡은 창작자에게 지급하는 로열티의 규모까지는 밝히고 있지 않습니다.
여기에서 질문이 하나 생깁니다. 이 로열티의 파이는 얼마나 커야 할까요? 구글브레인 소속 연구원 제시 엥겔이 트위터에서 던진 질문을 인용해봅니다. “데이터 생산자에게, 그 데이터로 학습한 인공지능이 발생시킨 수익 일부를 로열티로 지급하는 게 당연한 상황을 가정합시다. 얼마가 적당할까요?”
추신
파괴 투쟁으로 시작한 러다이트 운동은 탄압 끝에 민주주의 투쟁과 단체교섭권으로 이어졌습니다. 방적기가 상징하는 사회적 변화에 관한 협의가 작동한 곳은 결국 기술 장치보다는 민주 정치의 공간이었던 것이죠. ‘생성AI를 오염시킨 제2의 러다이트’는 오해였지만, AI 관련 논란이 권력과 자원 분배에 관한 논의를 풍부하게 한다면 새로운 러다이트 운동이라는 말도 무리가 아닐지 모릅니다.